智盟创课(北京)科技有限公司(简称 “智盟 Stu.”),作为专业IT产研培训服务供应商与AI时代数字化人才发展伙伴,为科技研发型企业及各类组织提供系统性、分层次、重实战的人才培养解决方案,同时搭建行业前沿技术交流平台,致力于成为企业数字化转型进程中人才培养与业务创新的核心支撑力量,推动组织实现成功转型及经营业绩持续增长。同时,智盟发起并组织四大 IT 领域品牌会议: QECon 软件质量效能大会、PMxAI 产品力领航者大会、Agentic AICon 智能体应用与架构工程大会,助力产研中心深化数字化转型、聚焦业务价值达成,在产品研发的快速交付与高质量发展之间找到平衡,打通企业全维度学习视角,最终实现人才能力提升与企业竞争优势增强的双重目标。

欢迎来到智盟创课!
大数据Hadoop&HDFS&MapReduce&Hive&HBase&Impala&Spark企业级最佳实战
尹老师 移动云计算专家,资深软件架构师
多年从事大数据、云计算研发工作经验,数学博士,北航移动云计算硕士,Coudera大数据认证(图1),项目管理师(PMP)认证(图2)主要研究方向包括云计算、大数据、移动开发、互联网营销、电子商务、项目管理等;某大型知名企业首席架构,负责PaaS平台研发。IT从业近二十年,秉承理论与实践相结合,在学习中实践,在实践中学习,积累了丰富的理论与实践经验,并且乐于将自己的经验分享。尹老师具有敏锐的目光与头脑,发现并集成整合社会资源,为企业节省资源并创造价值,达到为合作伙伴创收的目的。
课程特色
Hadoop生态系统是大数据技术事实标准,是大数据思想、理念、机制的具体实现,是整个大数据技术中公认的核心框架和具有极强的使用价值与研究价值。Hadoop 系统是一款开源软件,能够处理海量的各种结构(包括结构化、非结构化、半结构化)的数据。Yarn是基于Hadoop的分布式集群资源管理框架;随着Hadoop集群应用的广泛,以及集群的规模越来越大,人们发现Hadoop MRv1存在诸多问题,因此Hadoop MRv2诞生,即现在的YARN,解决了4000节点的上限问题。
基于 Hadoop 的解决方案能够帮助企业应对多个大数据挑战,包括:
- 分析海量(PB 级或者更多)的数据 (Hadoop 能够分析所有数据,使得分析更准确,预测更精确;)
- 从多个数据类型的组合中获得新的洞察力 (将来自多个数据源的不同类型的数据进行结合分析,发现新的数据关系和洞察力;)
- 存储大量的数据 (由于它不依赖于高端硬件,且是可扩展的,所以使存储大量数据变得经济有效;)
- 数据发现(data discovery)和研究的沙箱 (Hadoop 提供了一个地方,数据科学家可在此发现新的数据关系和相互依赖性。)
工业和信息化部电信研究院于2014年5月发布的“大数据白皮书”中指出:
“2012 年美国联邦政府就在全球率先推出“大数据行动计划(Bigdata initiative)”,重点在基础技术研究和公共部门应用上加大投入。在该计划支持下,加州大学伯克利分校开发了完整的大数据开源软件平台“伯克利数据分析软件栈(Berkeley Data Analytics Stack),其中的内存计算软件Spark的性能比Hadoop 提高近百倍,对产业界大数据技术走向产生巨大影响”
----来源:工业和信息化部电信研究院
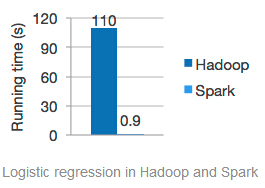
Spark是成为替代MapReduce架构的大数据分析技术,Spark的大数据生态体系包括流处理、图技术、机器学习等各个方面,并且已经成为Apache顶级项目,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。
国内外一些大型互联网公司已经部署了Spark,并且它的高性能已经得到实践的证明。国外Yahoo已在多个项目中部署Spark,尤其在信息推荐的项目中得到深入的应用;国内的淘宝、爱奇异、优酷土豆、网易、baidu、腾讯等大型互联网企业已经将Spark应用于自己的生产系统中。国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。在2014 Spark Summit上,世界20家顶级公司声明支持Spark,这些公司包括了最大的四个Hadoop发行商Cloudera, Pivotal, MapR, Hortonworks,都提供了对非常强有力的支持Spark的支持:
- Hadoop的头号发行商Cloudera,在2014年7月份宣布“Impala’s it for interactive SQL on Hadoop; everything else will move toSpark”;
- 2014年5月24日Pivotal宣布了会把整个Spark stack包装在Pivotal HD Hadoop发行版里面;这标志着四个Hadoop发行商Cloudera、Pivotal、MapR、Hortonworks都提供了对Spark的支持;
- 2014年4月,Mahout表示将不再接受任何形式的以MapReduce形式实现的算法,Mahout宣布新的算法基于Spark;
- Cloudera的机器学习框架Oryx的执行引擎也将由Hadoop的MapReduce替换成Spark;
培训目标
- 大数据生态圈各组件介绍,包括应用场景、架构原理等,主要包括Hadoop、HDFS、MapReduce、Hive、HBase、Spark;
- 大数据平台搭建的实战,侧重讲解平台建设的安全性、性能调优、实际案例分析,基础搭建知识不需要过多讲解;
- 大数据实战,大数据项目中架构,技术选型,安全保障等,以及经验分享;
- ETL基础组件Flume、Sqoop架构与使用,包括数据清洗的实际使用案例介绍;
- 通过该课程学习使学员具备Hadoop企业级大数据管理与应用的能力;
- 通过该课程学习使学员具备Hive企业级大数据分析的能力;
- 通过该课程学习使学员具备HBase企业级大数据分布式NoSQL数据库的开发能力;
培训对象
- 对大数据、分布式存储、分析等感兴趣的朋友;
- Java、PHP、C等任意一门编程语言的开发者;
- 大型网站、电商网站等运维人员;
- 云计算、大数据从业者;
- 熟悉Hadoop生态体系,想了解和学习Hadoop与Spark整合在企业应用实战案例的朋友;
- 系统架构师、系统分析师、高级程序员、资深开发人员;
- 牵涉到大数据处理的数据中心运行、规划、设计负责人;
- 政府机关,金融保险、移动互联网等大数据单位的负责人;
- 高校、科研院所大数据研究人员,涉及到大数据与分布式数据处理的人员;
- 数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员;
培训方式
以课堂讲解、演示、案例分析为主,辅以互动研讨、现场答疑、学以致用。
课程内容内容
| 第一天 |
| 第1个主题: 大数据介绍(深入剖析大数据)(90分钟) |
| 1、 什么是大数据 2、 大数据的特征 3、 大数据应用现状 4、 大数据发展趋势 5、 大数据生态体系介绍 6、 大数据优势 7、 大数据的核心技术 8、 大数据与云计算之间的关系剖析 9、 大数据与虚拟化之间的关系剖析 10、 大数据与供应商剖析 11、 大数据与成本投入的关系剖析 12、 实例分享:马云预测经济危机案例剖析(20分钟) |
| 第2个主题: Hadoop生态体系(系统理解Hadoop生态体系)(120分钟) |
| 1、 什么是Hadoop 2、 Hadoop由来介绍 3、 Google四篇论文的剖析 a) GFS、MapReduce、BigTable、Chubby 4、 Hadoop的四大核心组件 5、 Hadoop相关概念 a) 块、副本 6、 Hadoop是大数据架构的事实标准 7、 Hadoop的四大核心组件 8、 Hadoop生态体系介绍 9、 Pig Hadoop客户端 10、 HBase大数据分布式NoSQL列式数据库 11、 Hive大数据的数据仓库 12、 Zookeeper分布式协调器 13、 Sqoop大数据导入导出工具 14、 Avro大数据系列化工具 15、 Chukwa大数据分布式数据收集系统 16、 Cassandra大数据分布式NoSQL列式数据库 17、 Ambari提供监控、管理Hadoop资源的工具 18、 Mahout Hadoop数据挖掘算法库 19、 Spark大数据内存计算框架 20、 Tez通用的数据流框架 21、 Hadoop 的数据文件格式介绍:JSON, SequenceFile, Avro 与 Parquet |
| 第3个主题: Hadoop集群(深入理解Hadoop集群并部署Hadoop集群)(90分钟) |
| 1、 Hadoop工作原理及架构 2、 Hadoop部署规划 3、 Hadoop部署优化 4、 Hadoop安全管理 5、 Hadoop HA部署介绍 6、 Hadoop集群的监控 7、 动态增加Hadoop的Slave节点 8、 Hadoop集群的运维 9、 Hadoop 集群的多租户架构 10、 Hadoop 安全体系 11、 案例分享:基于共享存储的Hadoop集群部署案例分享(10分钟) 12、 案例分享:基于云计算集群的Hadoop集群部署案例分享(10分钟) 13、 课堂实操:启动Hadoop集群4台机器(10分钟;老师带领学员一起操作,及学员问题指导员) |
| 第4个主题: HDFS大数据分布式文件系统(深入理解大数据分布式文件系统的原理与机制)(120分钟) |
| 1、 HDFS架构剖析 2、 NameNode、DataNode、SecondaryNameNode介绍 3、 NodeName高可靠性最佳实践 4、 DataNode中Block划分的原理和具体存储方式 5、 CLI操作HDFS 6、 Java操作HDFS 7、 RESTful操作HDFS 8、 动态修改Hadoop的Replication数目 9、 Hadoop序列化 10、 Hadoop流压缩 11、 Hadoop RPC 12、 SequenceFile与MapFile 13、 Hadoop Avro 14、 课堂实操:Hadoop与RAID之间的关系 15、 课堂实操:Java语言读写HDFS文件系统(时长:20分钟;老师带领学员一起操作,及学员问题指导员) |
| 第二天 |
| 第5个主题: YARN剖析(深入理解YARN的原理和使用YARN的能力)(30分钟) |
| 1、 YARN介绍 2、 YARN的设计思想 3、 YARN的核心组件 4、 YARN为核心的生态系统 5、 Yarn的HA机制 6、 YARN应用程序编写 7、 ResourceManager深入剖析 8、 ClientRMService与AdminService 9、 NodeManager深入剖析 10、 Container |
| 第6个主题: MapReduce大数据批处理技术(深入理解MapReduce原理及培训开发MapReduce程序能力)(120分钟) |
| 1、 MapReduce算法剖析 2、 MapReduce数据输入和输出; 3、 MapReduce编程思想 4、 MapReduce命令操作 5、 MapReduce运行过程解析 6、 Hadoop的调度器介绍 7、 Combiner的使用原则 8、 Partitioner的使用最佳实践 9、 MapReduce排序算法剖析 10、 用Streaming写MapReduce程序 11、 MapReduce 程序的单元测试程序; 12、 Hadoop API 的深度钻研; 13、 实践性的开发窍门和技术; 14、 Partitioners 和Reducers; 15、 子查询、触发器等常见性能问题分析及优化; 16、 MapReduce 作业中实现不同数据集的连接操作; 17、 课堂实操:Java语言编写MapReduce程序、运行MapReduce程序、查看运行结果(时长:20分钟,老师带领学员一起操作,及学员问题指导员) 18、 课堂实操:Java语言编写MapReduce实现马云预测经济案例 |
| 第7个主题: 大数据分析技术Pig介绍(介绍大数据分析工具Pig)(60分钟) |
| 1、 Pig 设计的目标 2、 Pig Latine介绍 3、 Pig关键性技术 4、 Pig的实用案例 |
| 第8个主题: 大数据数据仓库工具Hive介绍(大数据分析工具深入剖析与应用案例介绍)(120分钟) |
| 1、 Hive简介 2、 Hive的组件与体系架构 3、 Hive架构 4、 Hive vs RDBMS 5、 Hive的高可用部署方案 6、 Hive Data Types 7、 Hive安装模式 8、 Hive安装部署 9、 Hive Shell 10、 Hive API开发演示 11、 Hive中UDF和UDAF 12、 Hive数据分析 13、 课堂实操:Hive金融交易数据统计分析(时长:40分钟,老师带领学员一起操作,及学员问题指导员) |
| 第三天 |
| 第9个主题: Zookeeper大数据分布式协调器介绍(深入理解分布式协调器技术原理)(60分钟) |
| 1、 Zookeeper介绍 2、 Paxos算法 3、 Paxos 算法应用场景 4、 Zookeeper的数据模型 5、 Zookeeper的节点 6、 Zookeeper的角色 7、 Zookeeper工作原理 8、 Leader选举 9、 部署ZooKeeper 10、 Shell操作Zookeeper 11、 Java程序操作Zookeeper 12、 Zookeeper典型使用场景 |
| 第10个主题: HBase大数据NoSQL技术介绍(深入理解分布式NoSQL技术及原理)(120分钟) |
| 1、 HBase介绍 2、 HBase的特点 3、 HBase逻辑模型 4、 HBase列族与列 5、 HBase时间戳 6、 行式数据库 vs 列式数据库 7、 HBase物理模型 8、 数据存储结构:LSM 9、 HBase的REST接口 10、 HBase安装部署 11、 HBase Shell 12、 倒排索引 13、 HBase应用场景介绍 14、 开发实践分享:微博 15、 课堂实操:基于HBase开发微博实时大数据系统(时长:60分钟,老师带领学员一起操作,及学员问题指导员) 16、 HBase Filter 17、 HBase Coprocessor |
| 第11个主题: 大数据ETL工具介绍(介绍大数据ETL工具,包括:Sqoop、Flume)(120分钟) |
| 1、 Sqoop简介 2、 Sqoop架构 3、 Sqoop安装 4、 Sqoop Shell 5、 Sqoop应用场景介绍 6、 课堂实操:Sqoop借记卡数据导入与导出(时长:20分钟,老师带领学员一起操作,及学员问题指导员) 7、 Flume简介及使用 8、 Flume架构 9、 Flume数据源类型 10、 Flume收集数据2种主要工作模式 11、 Flume应用场景介绍 12、 课堂实操:电商客户日志收集(时长:20分钟,老师带领学员一起操作,及学员问题指导员) |
| 第四天 |
| 第12个主题: Oozie介绍(介绍Oozie的工作原理)(30分钟) |
| 1、 Oozie介绍 2、 Oozie设计思想 3、 Oozie架构 4、 Oozie特点 5、 Oozie数据加工流程设计 6、 Oozie企业应用案例 7、 Oozie异常处理与监控机制 8、 案例开发 |
| 第13个主题: 大数据内存计算技术介绍(深入理解Spark实现原理)(120分钟) |
| 1、 Scala介绍 2、 Mesos介绍 3、 Spark介绍 4、 Spark基本概念介绍 5、 Spark架构剖析 6、 Spark RDD计算模型解析 7、 Spark的执行机制解析 8、 DAG有向无环图介绍 9、 Spark的调试与任务分配 10、 Spark编程 a) Java编写Spark程序 b) Scala编写Spark程序 c) Python编写Spark程序 d) R编写Spark程序 11、 Spark可访问的数据源介绍 e) 文件系统 f) HDFS g) HBase h) Hive i) Cassandra j) Tachyon 12、 Spark与MapReduce对比分析 13、 Spark的容错机制剖析 14、 Spark集群部署 15、 Spark Shell 16、 构建与运行Spark应用 17、 Spark RDD操作剖析 18、 Shark基于Spark的综合应用 19、 Spark开发分析 20、 Spark作业测试解析 21、 Spark的性能调优 22、 Spark生态体系剖析 23、 Spark应用现状 24、 Spark应用优势 25、 Spark应用案例 26、 Spark案例解析 |
| 第14个主题: Impala介绍(介绍Impala的工作原理)(120分钟) |
| 1、 Impala介绍 2、 Impala是什么 3、 Impala与Hive、Pig有何不同 4、 Impala与关系数据库有何不同 5、 Impala的限制和未来发展方向 6、 运用 Impala Shell 7、 Impala分布式集群部署 8、 Impala分布式架构原理 9、 Impala数据模型 10、 Impala作业基本运行原理 11、 Impala使用注意事项 12、 Impala DDL、DML、SQL、函数 13、 Impala作业资源占用 14、 案例:银行在线支付统计的案例 15、 Impala调优可概述 16、 Impala参数调优 17、 Impala SQL调优 18、 Impala分区调优 19、 其他常用调优方法 20、 数据倾斜处理方法 21、 Impala与Shark、Hive、Pig区别剖析 22、 案例:Impala调优案例 |
| 第15个主题: Spark SQL技术实战(深入理解Spark SQL实现原理及开发实战)(120分钟) |
| 1、 Spark SQL概述 2、 Spark SQL原理剖析 3、 Spark SQL架构介绍 4、 SparkSQL CLI 5、 Tree和Rule 6、 sqlContext和hiveContext的运行过程 7、 Load/Save函数 8、 Parquet文件读写 9、 Spark SQL连接JDBC 10、 Spark SQL连接ODBC 11、 Spark SQL分布式文件HDFS读写 12、 JSON数据集 13、 Hive表 14、 数据类型 15、 Spark SQL与Cassandra集成 16、 Spark SQL APIs全面介绍 17、 Spark SQL and DataFrames 18、 Spark SQL and DataSets 19、 Spark SQL HiveQL 20、 Spark SQL编程 21、 运行Spark SQL程序 22、 在内存中缓存数据 23、 Spark SQL UDFs 24、 Spark SQL UADFs 25、 Spark SQL SerDes 26、 Spark SQL BI Tools 27、 Spark SQL实战案例:数据分析案例剖析 |
| 第五天 |
| 第16个主题: Spark Streaming流计算技术实战(深入理解Spark Streaming实现原理及开发实战)(120分钟) |
| 1、 Spark Streaming概述 2、 Spark Streaming原理剖析 3、 Spark Streaming流数据处理框架介绍 4、 Spark Streaming编程剖析 5、 初始化StreamingContext 6、 Discretized Streams (DStreams) 7、 输入DStreams与Receivers 8、 基于DStreams的Transformations 9、 基于DStreams的输出操作 10、 Accumulators和BroadcastVariables 11、 DataFrame和SQL操作 12、 MLlib操作 13、 Caching与Persistence 14、 Checkpointing 15、 运行Spark Streaming程序 16、 性能调优:减少批处理时间 17、 性能调优:设置正确的批处理间隔时间 18、 内存调优 19、 容错元语 20、 实战案例:Spark Streaming与Kafka整合实现数据实时数据分析处理设计与分析 |
| 第17个主题: 大数据实时计算技术(深入理解Storm实现原理)(120分钟) |
| 1、 Storm基础知识 2、 Storm集群安装 3、 Storm打包运行测试 4、 Storm基本api介绍 5、 Storm Topology的并发度 6、 Storm消息机制原理讲解 7、 Storm DRPC实战讲解 8、 Storm Transaction原理 9、 Strom Trident编程 10、 Storm案例实战 |
| 第18个主题: 分布式消息中间件Kafka剖析(深入理解Kafka的实现原理)(60分钟) |
| 1、 Kafka诞生背景剖析 2、 什么是Kafka 3、 Kafka特征剖析 4、 Kafka架构剖析 5、 Broker 6、 Producer 7、 Consumers 8、 Topics 9、 Leader 10、 Follower 11、 Kafka集群部署 12、 队列模式(queuing) 13、 发布-订阅模式(publish-subscribe) 14、 Kafka创建topic、发送消息、消费消息 15、 数据传输的事务定义 16、 数据的持久化 17、 Kafka存储在硬盘上的消息格式 18、 Kafka节点管理 19、 Kafka运维管理 20、 Kafka主从同步 21、 Kafka的性能优化 22、 Kafka的消息与日志 23、 Kafka实战案例: |
| 第19个主题: Kafka Shell操作实战(全面深入理解Kafka相关命令和具备Kafka的运维能力)(60分钟) |
| 1、 Kafka Shell介绍 2、 Kafka查看日志命令 3、 Kafka主从命令 4、 Kafka监控命令 |
| 第20个主题: 编写Kafka程序(深入理解Kafka的APIs并动手实践)(60分钟) |
| 1、 搭建Kafka开发环境 2、 Driver程序开发 3、 Producer程序开发 4、 Consumer程序开发 5、 发布与运行 6、 Kafka APIs全面剖析 7、 Kafka APIs应用场景剖析及案例 8、 Kafka程序监控 9、 Kafka实战案例:Kafka整合实现数据实时数据分析处理设计与分析 |
第21个主题: 开源分布式搜索引擎Solr技术剖析(大数据时代开源搜索引擎)(60分钟) |
| 1、 Solr介绍 2、 Solr架构介绍 3、 Solr集群部署 4、 Solr缓存配置 5、 Solr操作介绍 6、 数据索引 7、 爬取与索引Web页面 8、 分析文本数据 9、 检索查询 10、 Solr性能优化 11、 Solr维护与管理 12、 Solr问题处理 13、 Solr插件功能 14、 案例:基于Solr实现项目的全文检索功能 |
| 第22个主题: morphline日志解析(大数据日志解析工具)(60分钟) |
| 1、 morphline简介 2、 morphline架构模型 3、 morphline功能介绍 4、 morphline的处理模型 5、 morphline强大的正则提取器grok 6、 服务端使用morphline 7、 实战案例:morphline日志解析实战 |

智盟创课公众号
智汇|共创|互联|共成长
400-183-9980
010-65798049
服务总线
咨询热线
business@zmengstu.com
@2016 智盟创课(北京)科技有限公司 版权所有
